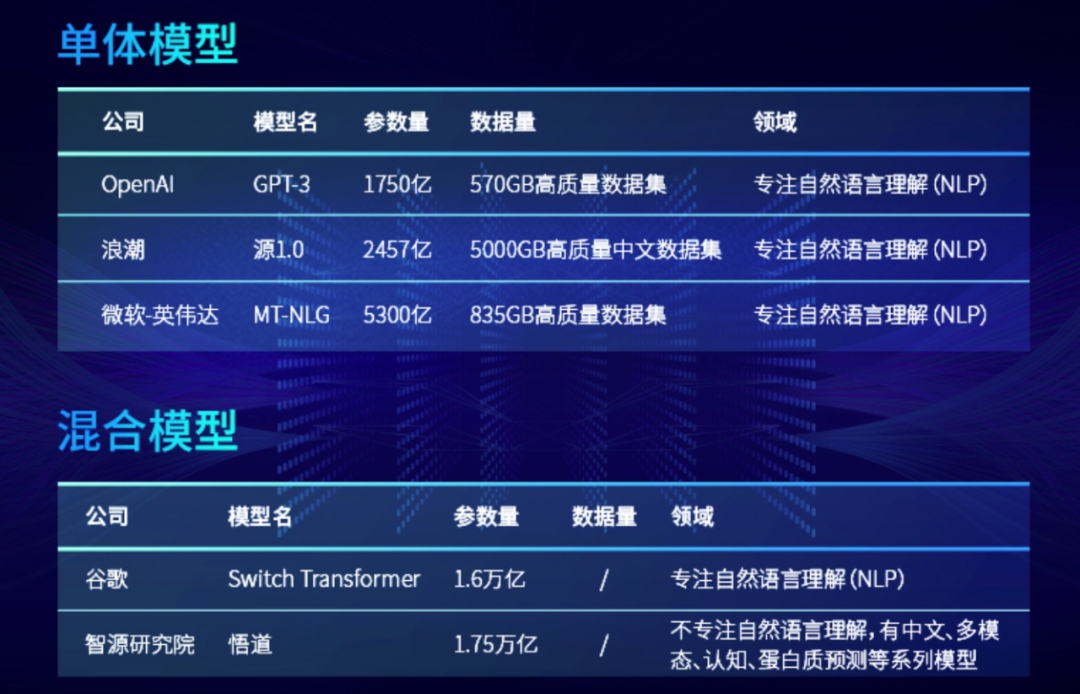
360智脑7B参数大模型正式开源
4月12日,三六零自研人工智能大模型360智脑7B参数模型正式开源,包括4K、32K、360K三种文本长度,现已上线Github开源社区,在360K长度下,可支持50万字左右输入,三秒钟即可读完《三体》。经过与国内外同参数模型进行权威测评对比,该模型综合能力位居前三。除模型权重外,该模型的微调训练代码,推理代码等全套工具集也被一并开源,大模型相关开发者可做到“开箱即用”,大模型行业借此可正式告别“长文本内卷”。

图片来源于网络,如有侵权,请联系删除
目前,“长文本”已成为国产大模型技术突破点,受到行业普遍关注。据了解,360智脑此次开源的7B 360k模型,为当前国产开源模型中文本长度最长。“定360K主要是为了讨个彩头”,此前,360集团创始人周鸿祎在与知名投资人朱啸虎的对谈中透露过该大模型的相关信息,并称自己相信开源的力量。
通过使用OpenCompass与国内外同参数模型进行对比,360智脑7B模型综合平均分可达到前三,在C-Eval、MMLU、HellaSwag、LAMBADA四个评测数据集上达到第一,充分反应出该模型在中英文知识和理解推理能力方面的能力。当前,百度“弱智吧”帖子中的问题已成为验证大模型智能性的重要参考,360智脑7B模型在相关评测中表现亮眼,侧面印证了该模型的逻辑推理能力。
360智脑7B与同级别参数大模型能力对比评测中位居前三
据了解,360智脑7B模型在技术实现上抛弃滑动窗口attention、跳跃attetion等有损压缩路线,采用的是超长文本的无损压缩技术。为了解决随着序列长度的增长,模型训练的复杂度平方增长的挑战,360智脑在训练长文本模型时采用了两阶段的方式进行,采用了ABF+继续预训练,以及有监督的微调加以解决,有效解决了长文本模型在训练长度和训练效率上的问题,实现了高效的长文本拓展方法。在训练效率提升之下,综合智能性多项指标测评,360智脑7B在同等参数规模的情况下拿到了国内最高分。此外,在英文原版360k大海捞针效果同样取得了98.27%的高分。
360智脑7B大模型LongBench长文本评测得分最高
相关人士称,360智脑7B等国产自研大模型的开源,使“长文本”成为大模型的标配,进而推动国内大模型的场景化落地,为大模型在应用层创新提供重要支撑。随着以360为代表的互联网大公司将自研大模型开源,中国大模型产业将获得进一步发展。
【责任编辑:周靖杰】扫描二维码推送至手机访问。
版权声明:本文由经济快讯网发布,如需转载请注明出处。